스트라이드
콘볼루션 맵이 shift를 할 때, 얼마만큼의 step size를 할 것인가 ?
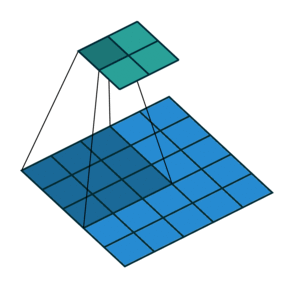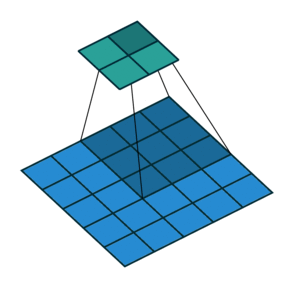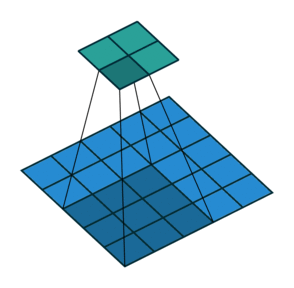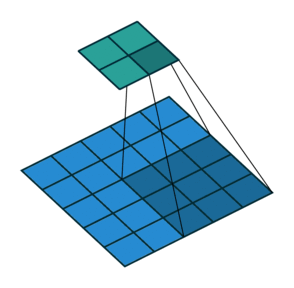
파란색이 input image이고
녹색이 activation map(output image)이다.
여기서 커널 사이즈는$ 3 \times 3 $이다.
스트라이드가 2칸이다.
스트라이드가 1일 경우에는 activation map의 사이즈가 $ 3 \times 3 $이다.
촘촘하게 shifting 할 필요가 없을 경우에는 스트라이드를 높여도 된다.
패딩
채워넣는 것이다.
input image가 $ 5 \times 5 $이고
kernel size가 $ 3 \times 3 $ 이면
패딩이 없을 경우 activation map의 사이즈는 $ 3 \times 3 $ 이다. 이미지가 줄어들었다.
입력 이미지 사이즈를 유지하고 싶을 때, 이미지의 경계에 0을 채워 넣는다. (zero padding)

0이기 때문에 새로운 정보가 들어간 것이 아니다.
패딩을 넣는 이유는 공간적으로 dimension을 일정하게 하고 싶을 때 넣는다.
콘볼루션이 완료되고 나면 여기까지는 선형결합이다.
비선형 액티베이션 함수를 추가해준다.
element-wise하게 씌운다. (모델에 비선형성을 추가하면 성능을 높일 수 있음)
풀링
액티베이션 함수까지 오고나서 풀링이라는게 올 수 있다.
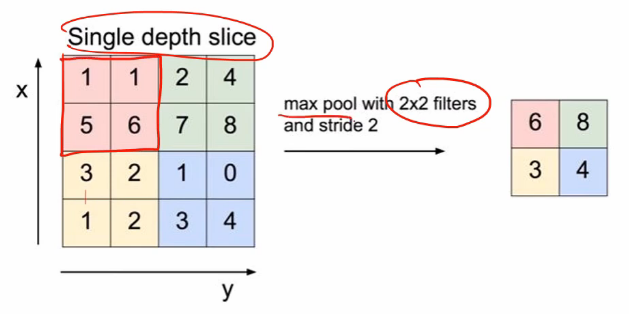
맥스풀링이라는 것은 max값을 고르는 것이다.
결과적으로 $ 4 \times 4 $ 가 $ 2 \times 2 $가 되었다.
사이즈가 줄어드는 역할을 했다.
맥스풀링의 경우
공간상의 resolution을 줄이는 것이다.(빠른 계산을 위해서)
로컬한 invariance를 유지한다.
풀링은 파라미터가 따로 없다.
왜 하느냐? 2가지 의미
1. 로컬한 invariance를 유지 (noise가 제거되는 것으로 볼 수도 있음.)
2. 사이즈를 줄여서 복잡도를 줄이는 것이다.
average-pooling도 있다.
일반적으로 맥스풀링을 많이 사용한다.
그리고, 맥스풀링의 경우 overlapping을 안하는 것이 좋다. 풀링의 장점을 살리는 것이므로.
1D에서의 풀링

grouping하는 것과 같다.
압축하는 느낌
풀링의 역할:Invariance

입력에서의 uncertainty를 줄여나가는 것이 있다.
인풋에 너무 민감하게 동작하지 않게 위한 의도도 있다.
멀티채널 풀링

풀링은 콘볼루션과 조금 다르게 채널하고 상관없이 w와 h만 정의가 된다.
채널별로 다 하는 것이다.
최종적으로 채널은 유지가 된다.
전체 흐름
Feature Learning
콘볼루션을 통해서 입력이미지에서 feature를 학습한다.
액티베이션 함수를 통해서 비선형성(non-linearity)를 추가한다.
풀링을 사용해서 공간적인 정보를 보존하면서 차원을 감소한다.

Classification
features를 fully connected해서 분류하는 것이다.
CONV와 POOL 레이어는 high-level features을 결과물로 내준다.
마지막 단에서는 이미지가 어디에 속했는지 확률로 표현한다. (softmax 사용)


CNN에서의 $ \omega $ ?
backpropagation으로 학습하는데 커널에 있는 element를 학습하는 것이다.
convolutional filter와 fully connected layers의 가중치를 학습한다.
분류문제면 cross-entropy loss를 사용해서 역전파를 한다.
Source: Dr. Francois Fleuret at EPFL
'머신러닝과 딥러닝' 카테고리의 다른 글
| ConvNet 학습 시각화 (히트맵 시각화) (0) | 2020.01.07 |
|---|---|
| ConvNet 학습 시각화 (중간층 출력의 시각화) (0) | 2020.01.07 |
| 콘볼루션에서의 커널 (0) | 2020.01.07 |
| 콘볼루션 뉴럴 네트워크(Convolution Neural Networks) (0) | 2020.01.07 |
| 이미지에서의 콘볼루션 (0) | 2020.01.06 |