인간과 자연 세상에서 일어나는 수많은 일을 설명하는 핵심 개념이다.
통계학에서 사용하는 각종 확률분포 중에서도 가장 중요하게 다루는 분포이다.
물리학 실험용으로 무작위 표본추출을 통해 도출한 확률밀도곡선에 극한을 적용해 만든 것을 형태로 정립한 것인데,
그 그래프를 함수식으로 풀어쓰면 다음과 같다. (σ : 표준편차, μ : 평균)
$$ N(\mu,\sigma^2)(x)=\frac {1} {\sigma \sqrt{2\pi}}e^\frac {-(x-\mu)^2} {2\sigma^2} $$
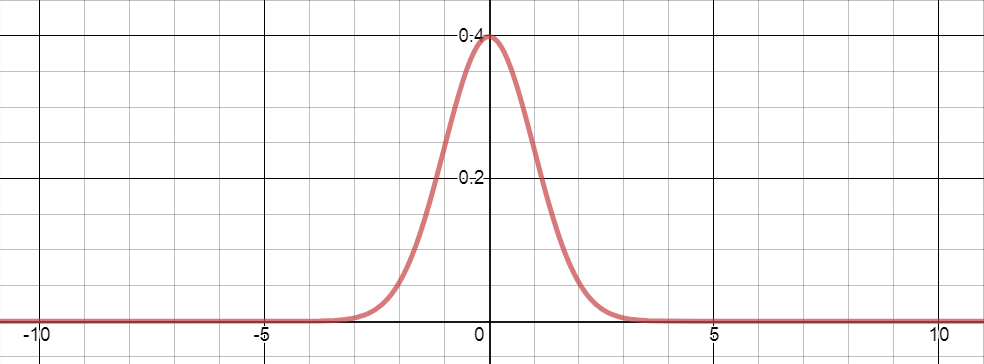
평균이 0이고 분산이 1인 표준정규분포의 밀도 곡선은 아래와 같다. 평균에 대해 좌우대칭이다.
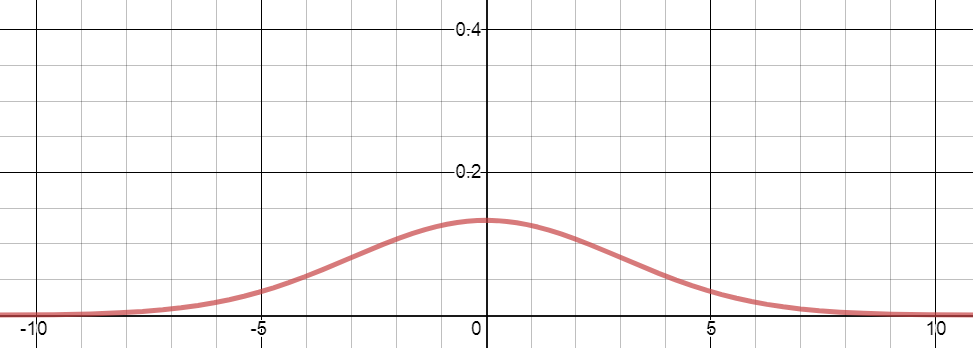
평균이 0이고 분산이 3인 정규분포의 밀도 곡선은 아래와 같다.
데이터 분포에 대한 사전지식이 전혀 없을 때 정규분포를 가정하는 것은 다음 두 가지 이유로 꽤 합리적인 선택이다.
첫번째로 중심극한정리이고, 두번째는 정규분포는 최대 불확실성을 내포하는 좋은 성질을 가지고 있기 때문이다.
중심극한정리
동일한 확률분포를 가진 확률변수 n개의 평균의 분포는 n이 충분히 크다면 '정규분포'에 가까워진다는 것이다. 즉, 알수 없는 모집단에서 표본이 충분히 커지면, 이 표본평균의 분포는 정규분포에 근사한다는 것이다.
동일한 확률분포를 가진 확률변수 n개의 평균의 분포는 n이 충분히 크다면 '정규분포'에 가까워진다는 것이다. 즉, 알수 없는 모집단에서 표본이 충분히 커지면, 이 표본평균의 분포는 정규분포에 근사한다는 것이다.

http://www.statisticalengineering.com/central_limit_theorem.htm
이항분포의 정규분포 근사
동전 던지기를 예로 들면 동전을 100번 던졌을 때 앞면이 0번 나올 확률부터 100번 나올 확률까지 나열하면 확률이 0.5 시행횟수 100인 이항분포이다.
일반적으로 성공확률 p인 베르누이 시행을 N번 시행하여 성공횟수 X의 분포를 이항분포라고 정의하고 B(N, p)로 표현한다.
평균은 Np, 분산은 Np(1-p)임이 알려져 있다. 여기서 n이 적당히 크다면 표본의 분포가 평균이 Np이고 분산이 Np(1-p)인 정규분포와 유사해진다. 아래 그림을 참고하자.
동전을 계속 던져보면?
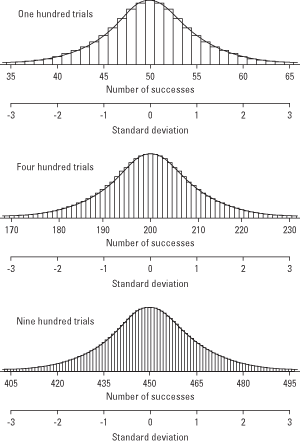
그래프의 모양을 선으로 그려보면 정규분포와 매우 유사해진다.
최대 불확실성의 내포
정보이론(Information Theory)에서 어떤 확률변수의 불확실성 측정하는 것을 바로 엔트로피(Entropy)라고 합니다.
이러한 엔트로피 h(x)를 구하는 공식은 다음과 같습니다.
$$h(x)=-\log_{2}p(x)$$
확률 p(x)에 log를 취하는 것은 바로 p(x)를 표시할 수 있는 자리 수(bit)를 나타낸다고 할 수 있다. 음수를 취하는 이유는 p(x)는 1보다 작기 때문에 log를 취하면 음수가 되기 때문이다. 계산하기 편하도록 양수로 변경하기 위해 적용하였다고 이해하면 된다.
p(x) = 0.01 일때 밑이 2인 log0.01는 -6.6438 값을 가진다.
h(x)는 따라서 6.6438값을 가진다.
그렇다면, 확률분포에 대한 기대값을 계산하는 방식으로 p(x)를 표시할 수 있는 공간을 나타내는 엔트로피를 계산해보면 다음과 같다.
$$H[x]=-\sum p(x)\log_{2}p(x)$$
어떤 랜덤 변수 x가 8가지의 상태가 동일한 확률로 발생한다고 할 때, 엔트로피는 다음과 같이 계산할 수 있다.
$$H[x]=-8\times \frac {1} {8} \log_{2} \frac {1} {8}=3bits$$
즉, 3bit의 데이터를 가지고 x가 발생할 확률을 모두 표현할 수 있다는 것이다.
만약 8개가 발생할 확률이 동일하지 않다면 어떻게 될까
만약 8개의 확률이 다음과 같이 다양하다고 할 때, 엔트로피를 계산해보자
$$(\frac {1}{2}, \frac {1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{64},\frac{1}{64},\frac{1}{64},\frac{1}{64})$$
$$H[x]=-\frac{1}{2}\log_2\frac{1}{2}-\frac{1}{4}\log_2\frac{1}{4}-\frac{1}{8}\log_2\frac{1}{8}-\frac{1}{16}\log_2\frac{1}{16}$$
$$-\frac{1}{64}\log_2\frac{1}{64}-\frac{1}{64}\log_2\frac{1}{64}-\frac{1}{64}\log_2\frac{1}{64}-\frac{1}{64}\log_2\frac{1}{64}=2bits$$
불균형한 분포를 보일 경우 엔트로피 값이 더 작아지는데, 예측해서 맞출 수 있는 확률이 높아 졌기 때문에 정보의 양, 즉 엔트로피가 더 작아진것이다.
불확실성이 높아질 경우( 분포가 균등적일 수록), 정보의 양은 더 많아지고 엔트로피는 더 커진다고 할 수 있습니다.
동전 던지기의 예를 살펴보자.
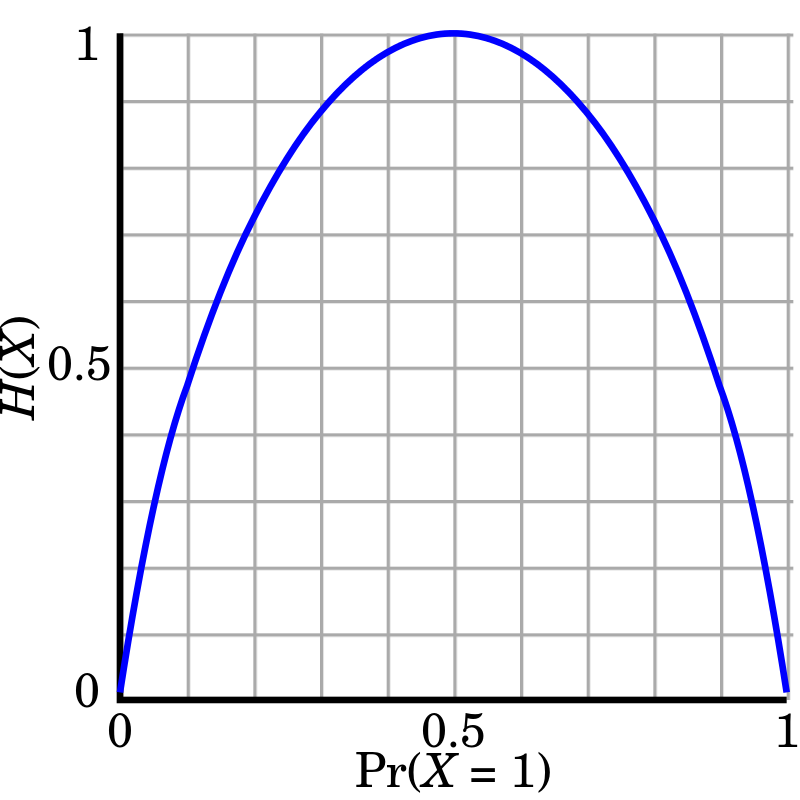
위 그래프는 동전을 한번 던졌을 때의 엔트로피 변화를 나타낸 것이다.
H(X)는 동전 던지기의 엔트로피를 나타내며, Pr(X=1)는 확률을 의미한다. X=1은 앞면 나오는 결과를 의미한다. 여기서, 최대 엔트로피는 1비트이다.
한 개의 동전 던졌을때, 2개의 가능한 값의 결과를 전달하기 위해서는 평균 1비트가 필요하다.
(앞뒤가 공정하게 나타나는 코인의 경우 정확히 1비트)
$$\log_22=1bit$$
주사위를 던졌을 때, 6개의 가능한 값을 전달하기 위해 필요한 비트는 다음과 같다.
$$\log_26=2.5849625007bits$$
엔트로피를 최대로 만드는 확률함수를 유도하면 정규분포 식이 도출된다고 한다. 따라서 정규분포를 가정할 경우 모델을 만들 때 사전 지식(prior knowledge)을 최대한 배제한다는 의미 또한 지니게 된다는 것이다.
또한, 정보이론의 핵심은 잘 일어나지 않는 사건(unlikely event)의 정보는 자주 발생할만한 사건보다 정보량이 많다고(informative) 하는 것입니다.
'기초통계' 카테고리의 다른 글
| 최대 우도 추정법(MLE) 예시 (0) | 2019.12.12 |
|---|---|
| MLE(Maximum Likelihood Estimation)와 MAP(Maximum A Posterior) (0) | 2019.12.11 |
| 로그 함수의 사용 의도 (1) | 2019.12.11 |
| 결합확률분포(추후 업뎃) (0) | 2019.12.01 |
| 베르누이 분포(Bernoulli Distribution) (0) | 2019.11.26 |